
Howdy folks!
I asked this at last night's meeting, as my "stumper of the month", but didn't get any solutions or leads. So, I thought I'd ask again here...
After upgrading many of our systems, both workstations and servers, from CentOS 5.x to Scientific Linux 6.x, I'm seeing higher load averages on idle systems than I used to. Under EL5, loads would drop to zero and pretty much stay there most of the time for idles systems. Under EL6, the load might drop down to 0.1, but doesn't stay there for very long, and even on seemingly idle systems, I see loads at or near 1 (sometimes even higher than 1 on some of our servers). It's also intermittent, with load averages dropping and climbing on fairly short intervals (of a few minutes or so).
Running top, iotop, ftop, iftop, etc. doesn't really point to any major culprits. I've even run PowerTop, and implemented some of its suggested improvements, but that didn't make a difference on load.
Just wondering if anyone else has seen similar behaviour with hosts running Red Hat and/or Fedora distributions? Would moving to the "tickless" kernel have anything to do with it? (I.e. does it somehow affect the way load averages are calculated?)
Or is it some system service that can be shut down? (If it is, it's not creating an obvious load on its own, that top or ftop would show, but it may be affecting something in the kernel...)
Any suggestions?

Which kernel version did you say they're running? Did you try running with "nohz=off"?
On Wed, Apr 11, 2012 at 5:00 PM, Gilbert E. Detillieux < gedetil@cs.umanitoba.ca> wrote:
Howdy folks!
I asked this at last night's meeting, as my "stumper of the month", but didn't get any solutions or leads. So, I thought I'd ask again here...
After upgrading many of our systems, both workstations and servers, from CentOS 5.x to Scientific Linux 6.x, I'm seeing higher load averages on idle systems than I used to. Under EL5, loads would drop to zero and pretty much stay there most of the time for idles systems. Under EL6, the load might drop down to 0.1, but doesn't stay there for very long, and even on seemingly idle systems, I see loads at or near 1 (sometimes even higher than 1 on some of our servers). It's also intermittent, with load averages dropping and climbing on fairly short intervals (of a few minutes or so).
Running top, iotop, ftop, iftop, etc. doesn't really point to any major culprits. I've even run PowerTop, and implemented some of its suggested improvements, but that didn't make a difference on load.
Just wondering if anyone else has seen similar behaviour with hosts running Red Hat and/or Fedora distributions? Would moving to the "tickless" kernel have anything to do with it? (I.e. does it somehow affect the way load averages are calculated?)
Or is it some system service that can be shut down? (If it is, it's not creating an obvious load on its own, that top or ftop would show, but it may be affecting something in the kernel...)
Any suggestions?
-- Gilbert E. Detillieux E-mail: gedetil@muug.mb.ca Manitoba UNIX User Group Web: http://www.muug.mb.ca/ PO Box 130 St-Boniface Phone: (204)474-8161 Winnipeg MB CANADA R2H 3B4 Fax: (204)474-7609 ______________________________**_________________ Roundtable mailing list Roundtable@muug.mb.ca http://www.muug.mb.ca/mailman/**listinfo/roundtablehttp://www.muug.mb.ca/mailman/listinfo/roundtable
Other semi-random questions: Any processes in uninterruptible sleep? What kind of video cards do the systems have? Anything weird in /proc/interrupts?
On Wed, Apr 11, 2012 at 6:24 PM, Kevin McGregor kevin.a.mcgregor@gmail.comwrote:
Which kernel version did you say they're running? Did you try running with "nohz=off"?
On Wed, Apr 11, 2012 at 5:00 PM, Gilbert E. Detillieux < gedetil@cs.umanitoba.ca> wrote:
Howdy folks!
I asked this at last night's meeting, as my "stumper of the month", but didn't get any solutions or leads. So, I thought I'd ask again here...
After upgrading many of our systems, both workstations and servers, from CentOS 5.x to Scientific Linux 6.x, I'm seeing higher load averages on idle systems than I used to. Under EL5, loads would drop to zero and pretty much stay there most of the time for idles systems. Under EL6, the load might drop down to 0.1, but doesn't stay there for very long, and even on seemingly idle systems, I see loads at or near 1 (sometimes even higher than 1 on some of our servers). It's also intermittent, with load averages dropping and climbing on fairly short intervals (of a few minutes or so).
Running top, iotop, ftop, iftop, etc. doesn't really point to any major culprits. I've even run PowerTop, and implemented some of its suggested improvements, but that didn't make a difference on load.
Just wondering if anyone else has seen similar behaviour with hosts running Red Hat and/or Fedora distributions? Would moving to the "tickless" kernel have anything to do with it? (I.e. does it somehow affect the way load averages are calculated?)
Or is it some system service that can be shut down? (If it is, it's not creating an obvious load on its own, that top or ftop would show, but it may be affecting something in the kernel...)
Any suggestions?
-- Gilbert E. Detillieux E-mail: gedetil@muug.mb.ca Manitoba UNIX User Group Web: http://www.muug.mb.ca/ PO Box 130 St-Boniface Phone: (204)474-8161 Winnipeg MB CANADA R2H 3B4 Fax: (204)474-7609 ______________________________**_________________ Roundtable mailing list Roundtable@muug.mb.ca http://www.muug.mb.ca/mailman/**listinfo/roundtablehttp://www.muug.mb.ca/mailman/listinfo/roundtable
On 2012-04-11 18:37, Kevin McGregor wrote:
Other semi-random questions: Any processes in uninterruptible sleep?
Nothing unusual... There will be the occasional process in a disk-wait state, but on an idle host, I don't see much of that. As I said, top and iotop aren't showing much activity at all.
Some I/O will be over NFS, which may cause longer-than-usual disk-wait states, but there aren't any critical files (e.g. binaries or shared libraries) that are over NFS. I don't think I'm seeing any more NFS activity than on previous system versions; in fact, it should be less, since some stuff that I used to share via NFS (like /usr/local/{bin,lib}) isn't anymore.
What kind of video cards do the systems have?
It varies... The workstations are almost all Intel i5's with "Integrated Graphics Chipset: Intel(R) Clarkdale" (i810 driver). Servers are mostly AMD64 processors with ATI Mach64 or Radeon graphics chipsets.
In any case, I'm seeing this sort of load pattern whether or not I'm running the Xorg server, so I don't think it's related to video chipsets.
Anything weird in /proc/interrupts?
Not really... All h/w interrupts seem reasonable. (I've already gone through PowerTop recommendations, and did some sysctl tweaking to reduce these.) Local timer (LOC) and rescheduling (RES) interrupt counts are the highest, but I think that's normal.
On 2012-04-11 18:24, Kevin McGregor wrote:
Which kernel version did you say they're running?
Currently running kernel-2.6.32-220.7.1.el6.x86_64. All RHEL6 systems run builds of kernel version 2.6.32.
Did you try running with "nohz=off"?
I haven't yet. I'll try that, but it was just a guess that it may be related to that, not based on any observations.
On 2012-04-11 17:00, I wrote:
After upgrading many of our systems, both workstations and servers, from CentOS 5.x to Scientific Linux 6.x, I'm seeing higher load averages on idle systems than I used to. Under EL5, loads would drop to zero and pretty much stay there most of the time for idles systems. Under EL6, the load might drop down to 0.1, but doesn't stay there for very long, and even on seemingly idle systems, I see loads at or near 1 (sometimes even higher than 1 on some of our servers). It's also intermittent, with load averages dropping and climbing on fairly short intervals (of a few minutes or so).
Problem solved (at long last)!...
It turns out the problem was with "hald" polling the CD/DVD-ROM drive every two seconds. I had previously dismissed that as the potential problem, given that this seemed to be no different than the way hald worked under EL5 systems.
Running top, iotop, ftop, iftop, etc. doesn't really point to any major culprits. I've even run PowerTop, and implemented some of its suggested improvements, but that didn't make a difference on load.
My bad... PowerTop had indeed recommended I disable polling in hald, but I wasn't sure I wanted to disable that feature, particularly on the workstations (not really needed on the servers, though). Also, as I said above, I didn't think this was any different than in EL5, but apparently it is.
Also, hald-addon-storage (the sub-process that does the polling) wasn't sticking around long enough to show a big CPU load in "top", particularly with the default 3 second update delay, but when I dropped the delay to 1/2 a second, I was seeing it show up briefly every once in a while. (I was also seeing the irqbalance process show up as well, and mistakenly thought it might be the culprit. This seemed to make sense at the time, since I was seeing higher loads on our 16-core servers than the dual-core workstations, but that was a red herring.)
Just wondering if anyone else has seen similar behaviour with hosts running Red Hat and/or Fedora distributions? Would moving to the "tickless" kernel have anything to do with it? (I.e. does it somehow affect the way load averages are calculated?)
Still not sure if the new kernel makes a difference or not, but there must be something different about the way hald-addon-storage interacts with it to do the polling in EL6, compared to EL5. (Or have they just made the polling more aggressive, by reducing the interval?)
Or is it some system service that can be shut down? (If it is, it's not creating an obvious load on its own, that top or ftop would show, but it may be affecting something in the kernel...)
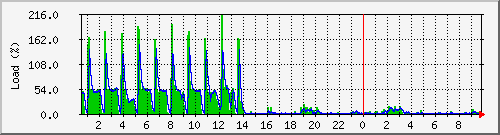
As you can see by the attached graph of the load average, disabling polling on the CD-ROM drive yesterday afternoon seems to have made all the difference. Here's the command PowerTop recommended:
hal-disable-polling --device /dev/cdrom
(Device name may vary.) The beauty of this, compared to disabling polling for all storage devices, is that you can disable it on a device basis, and keep polling enabled, e.g. for USB devices that might get inserted.
{kind=link}
-
 Gilbert E. Detillieux
Gilbert E. Detillieux -
 Kevin McGregor
Kevin McGregor